|
|
|
Modélisation des épidémies Des modèles pour comprendre la réalité Pour mieux combattre un virus et endiguer une épidémie, les chercheurs doivent d'abord comprendre comment elle évolue. Ils peuvent se baser sur les épidémies précédentes mais à condition que le virus soit similaire ainsi que la population. Dans le cas du SARS-CoV-2 (le Covid-19), c'est effectivement un nouveau coronavirus d'origine zoonotique mais sa vitesse de propagation est plus rapide que celle du SARS et du MERS. Il a donc fallu adapter ces modèles à la situation réelle. Lors d'une épidémie, les épidémiologistes aidés par des mathématiciens, des statisticiens et des programmeurs notamment développent des modèles informatiques dans le but de simuler et d'anticiper l'évolution de la contagion afin de conseiller les autorités sur les décisons à prendre en fonction de différents scénarii.
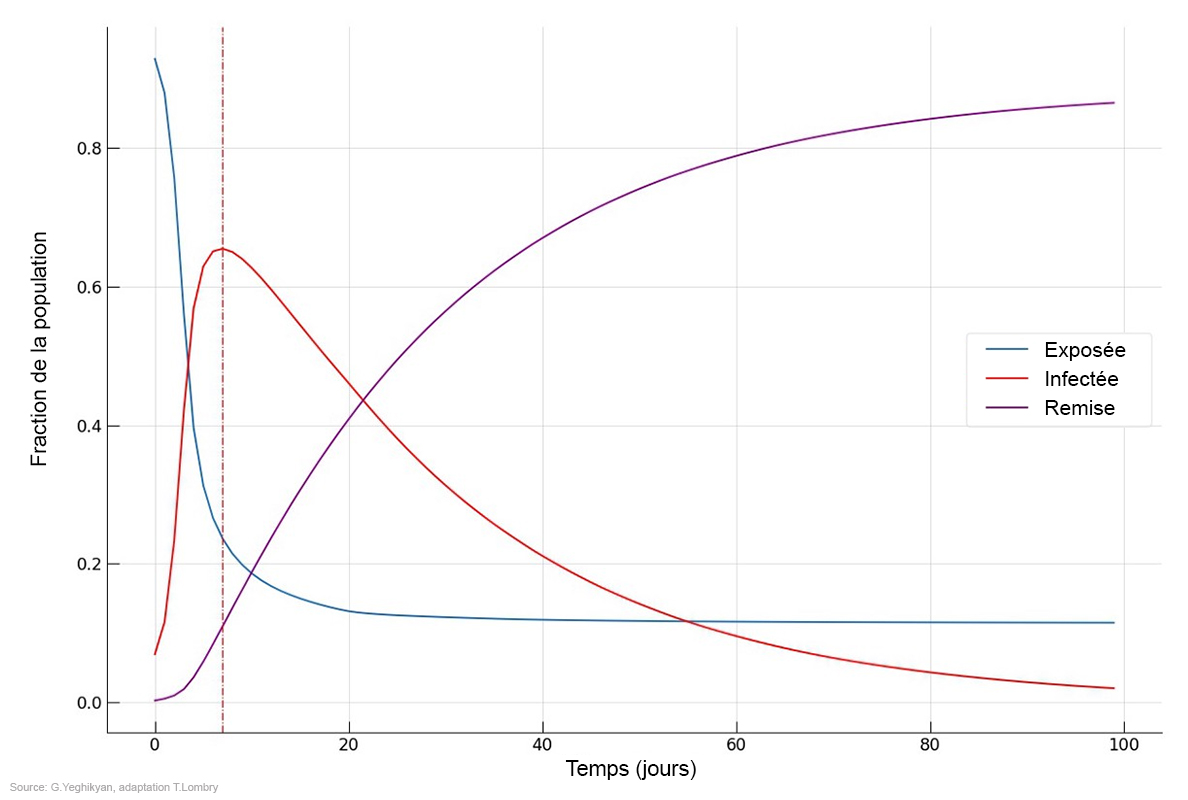
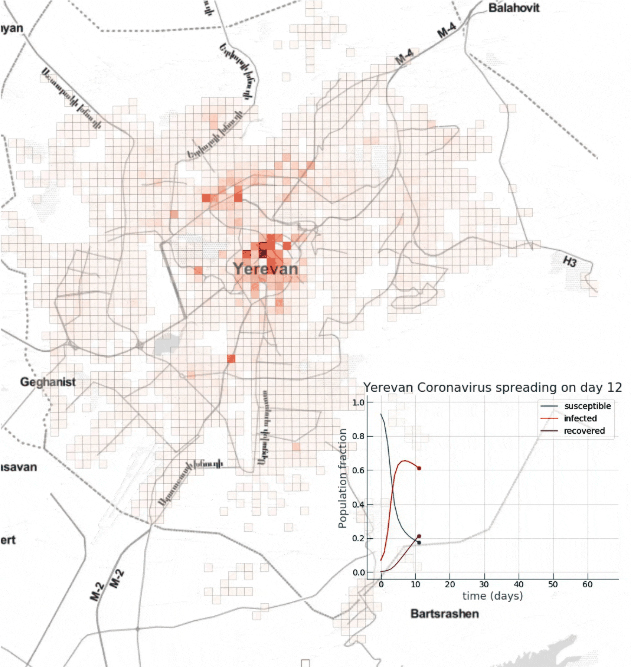
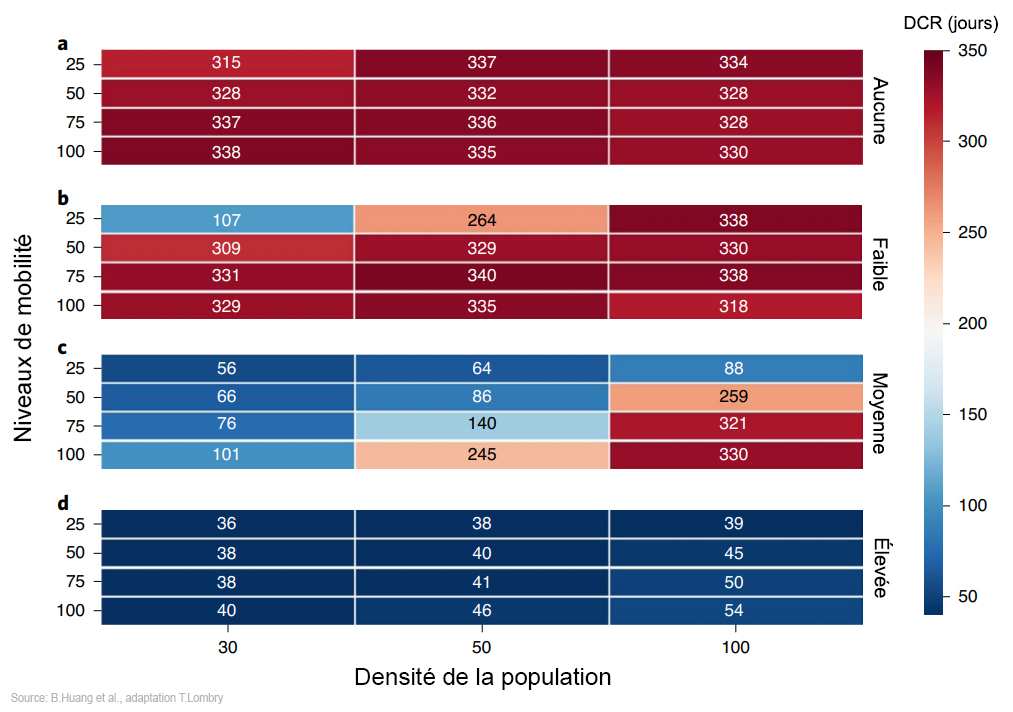
Ces modèles sont divisés en deux catégories : agrégés, à l'échelle des populations (modèle macroscopique) et distribués, à l'échelle des individus (modèle microscopique), la granularité variant du plus grand au plus petit. Les modèles agrégés Dans le cas du Covid-19, les chercheurs utilisent des modèles agrégés qui permettent de suivre l'évolution de l'état de plusieurs groupes de population qu'on appelle également des genres ou des compartiments. Le modèle le plus simple est le SIR qui n'utilise que 3 variables ou groupes de populations : saines, infectées et remise ((healthy, infected, recovered). Mais généralement on utilise le modèle SEIR qui considère 4 groupes de population : saine, exposée, infectée et remise (healthy, susceptible, infected, recovered). Pour certaines maladies comme la tuberculose ou les MST (SIDA, etc), on peut ajouter d'autres groupes de populations comme les porteurs asymptomatiques de la maladie (C pour Carrier), les décédés (D pour Decease) ou les individus disposant d'une immunité à la naissance (M pour Maternity-derived immunity), portant à 7 le nombre total de groupes de populations. Les volumes de ces groupes changent en fonction du taux de contagiosité du virus (Ro, voir plus bas) et des moyens mis en œuvre pour l'éradiquer. La contamination peut être contrôlée dans la mesure où elle repose sur trois facteurs ou critères : le nombre de contacts entre individus sains et infectés, la facilité de transmission lors d'un contact et la durée pendant laquelle les patients sont contagieux. Ensuite, on peut améliorer cette base de référence pour calculer la dynamique réelle de l'épidémie en intégrant d'autres critères comme les mouvements de populations (la mobilité) α, le taux de mortalité μ, le taux de natalité Λ, les expositions différenciées, les tranches d’âge, etc. A
voir : Simuler
une épidémie Exponential growth and epidemics - Ebola Outbreak Simulation A télécharger : Covid-19 Pandemic Simulator - Simulateur de l'épidémie au Covid-19 Agent Based Epidemic Model - SIR Agent Based Networks
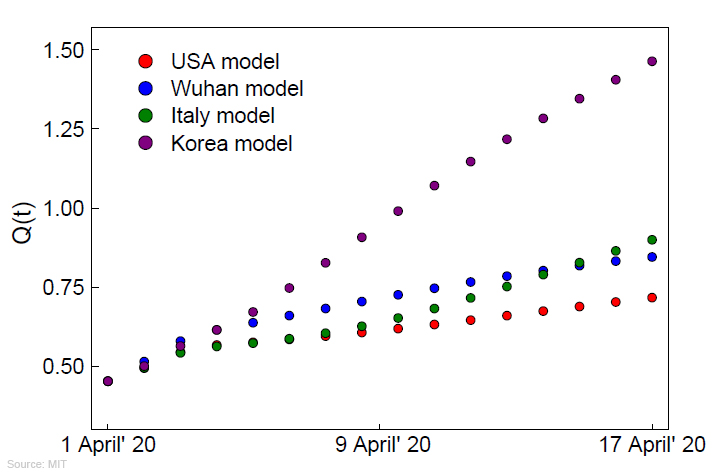
On peut étendre la méthodologie en développant un cadre théorique de stratégies de quarantaines dynamiques. Pour ce faire, on peut ajouter au modèle SEIR deux autres variables : les personnes placées en Quarantaine et celles en Isolement (cf. M.Mubayi et al. 2010). Enfin, le modèle SIR ou SEIR peut aussi être adapté pour modéliser l'effet de la vaccination. Dans ce cas on utilise un groupe supplémentaire V (Vaccinated individuals). Sans entrer dans les détails, puisque la somme N des variables est constante, on peut calculer la prévalence de la contamination virale, I/N qui définit l'état de santé de la population, c'est-à-dire le pourcentage de personnes atteintes par cette maladie à un instant donné. Il existe également une relation appelée le taux de transition entre S et I, β=N/I et entre I et R, γ=1/D avec D exprimé en unité de temps. On peut aussi calculer la force de l'infection F= βI, le taux de reproduction de base Ro = β/γ (ou Ro= βΛ/[μ(μ+ γ)]) sur lequel nous reviendrons. Le réseau neuronal au secours du modèle SEIR Durant la crise sanitaire de Covid-19, des chercheurs du MIT ont amélioré le modèle SEIR. Raj Dandekar, chercheur en génie civil et environnemental et son collègue George Barbastathis, professeur de génie mécanique furent les premiers à mettre l'apprentissage automatique de l'intelligence artificielle (IA), les fameuses "machine learning" au service de l'étude des épidémies. Ils ont amélioré le modèle SEIR en formant un réseau neuronal tenant compte des cas de contamination mis en quarantaine, c'est-à-dire des personnes qui ne peuvent plus propager le virus. Selon Dandekar, "Notre modèle est le premier qui utilise les données du coronavirus lui-même et intègre deux domaines : l’apprentissage automatique et l’épidémiologie standard" (cf. Dandekar et Barbastathis, 2020). Sachant que les personnes contaminées mises en quarantaine affectent le taux de contamination, les chercheurs ont créé un réseau neuronal de 500 itérations afin qu'il apprenne lui-même comment prédire les tendances de la propagation du virus. Selon Dandekar : "Le réseau de neurones apprend ce que nous appelons la “fonction de force de contrôle de la quarantaine”", autrement dit il permet d'évaluer l'efficacé d'une mesure de quarantaine. Grâce à ce modèle, les chercheurs ont pu établir une corrélation entre les mesures de quarantaine et la réduction du taux de contagiosité Ro.
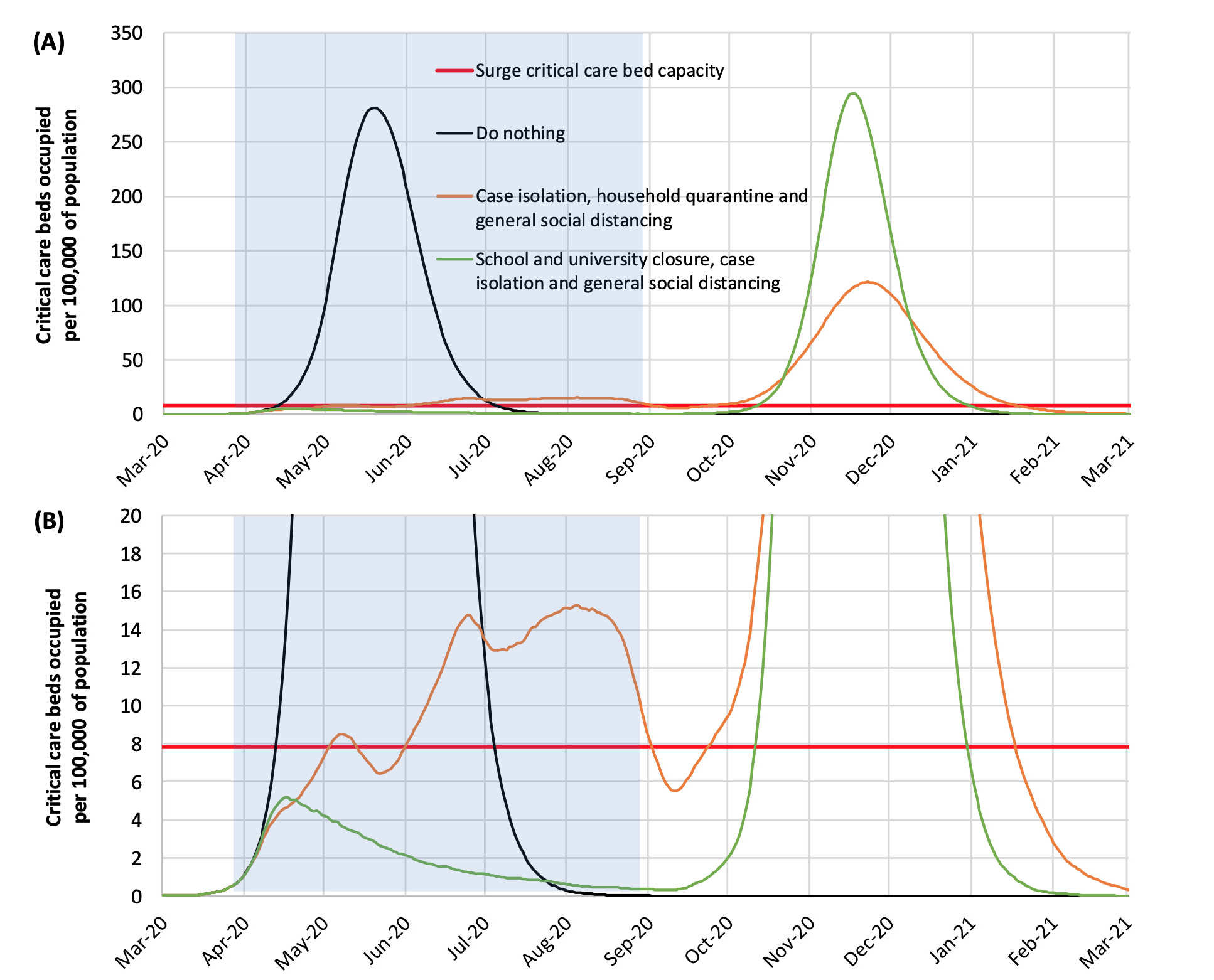
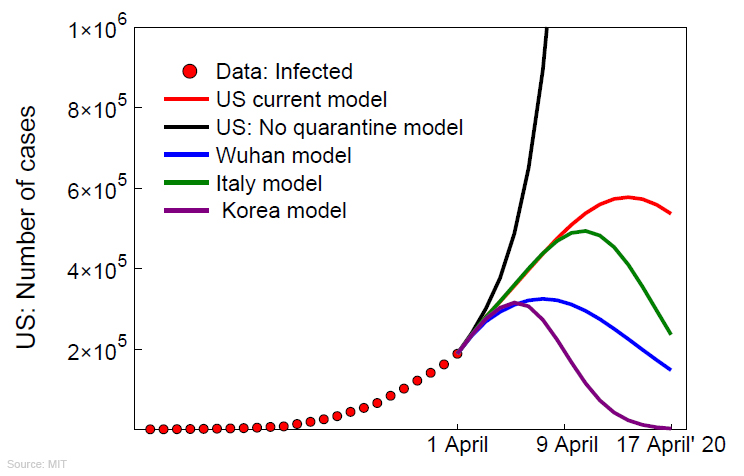
Ainsi qu'on le voit sur les graphiques présentés ci-dessus, lorsque des mesures de quarantaine strictes sont appliquées comme en Corée du Sud (et dans d'autres pays), que la population porte un masque facial de protection en public parmi d'autres consignes, on constate la formation d'un plateau plus ou moins tôt selon le modèle (la stratégie adoptée par le pays); le nombre de cas de contamination n'augmente plus et qu'il y a moins de personnes contaminées. Autrement dit la propagation du virus s'est stabilisée plus ou plus ou moins tôt, ce qui permet d'établir des prévisions sur l'occupation des lits d'hôpitaux. Ce contrôle de la quarantaine est donc efficace pour réduire le nombre de nouvelles contaminations. En revanche, dans les pays ayant appliqué tardivement ces mesures comme en Italie ou aux Etats-Unis, le virus s'est propagé de manière exponentielle, avec un Ro largement supérieur à 1 (voir plus bas). Ce modèle SEIR amélioré par l'apprentissage automatique d'un réseau neuronal permet également de calculer le nombre maximum de contaminations qu'atteindra un pays (le sommet des courbes dans le diagramme présenté ci-dessus à gauche) avant que l'épidémie ne stagne et qu'ensuite le virus disparaisse. Enfin, ce modèle SEIR neuronal permet de prédire quand l'épidémie passera d'un régime exponentiel à un régime linéaire. Il peut calculer à moins d'une semaine l'arrivée du plateau et donc quand le nombre de cas va diminiuer. Ainsi, on constate ci-dessus à droite que pour l'Italie (tracé vert) et les États-Unis (tracé rouge), le plateau était prévu entre le 15 et le 20 avril 2020, à condition que la population continue à respecter les consignes, au risque que le pays soit frappé par une deuxième vague épidémique. Selon les épidémiologistes et les infectiologues, connaître les dates du pic épidémique et du démarrage du plateau sont des moments cruciaux car si le gouvernement assouplit trop tôt les mesures de confinement et de quarantaine, cela pourrait conduire à une catastrophe sanitaire. C'est un risque que malheureusement une certaine partie du public irresponsable ne comprend pas, d'où la nécessité d'encadrer les mesures gouvernementales par un contrôle strict du pouvoir exécutif. A
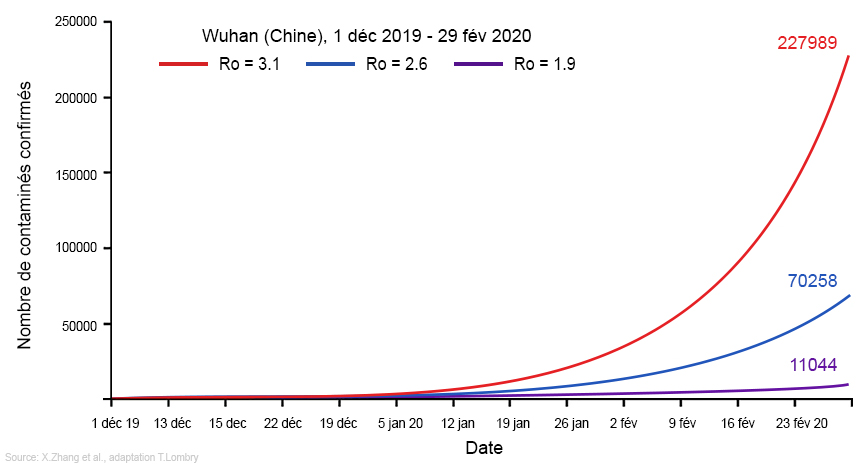
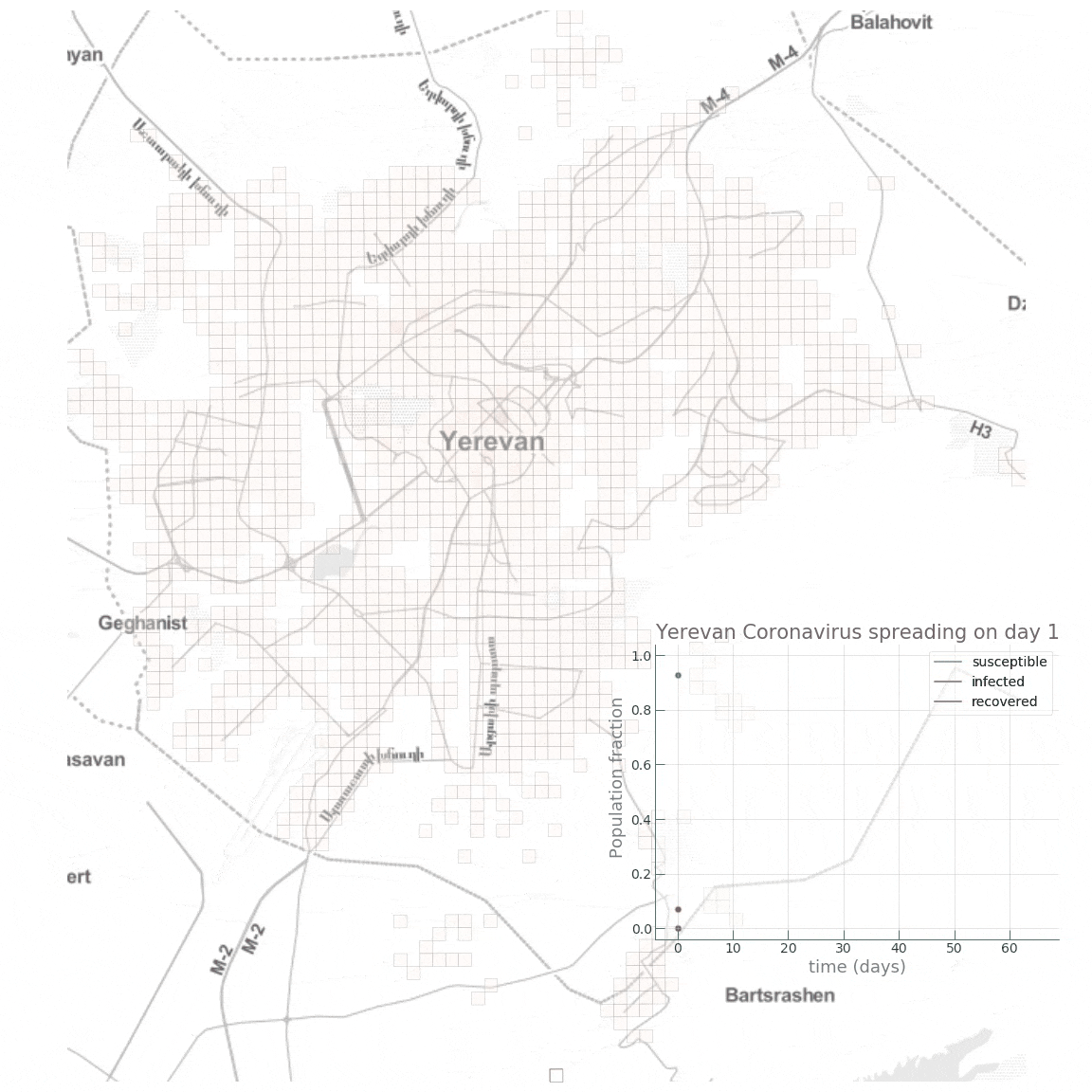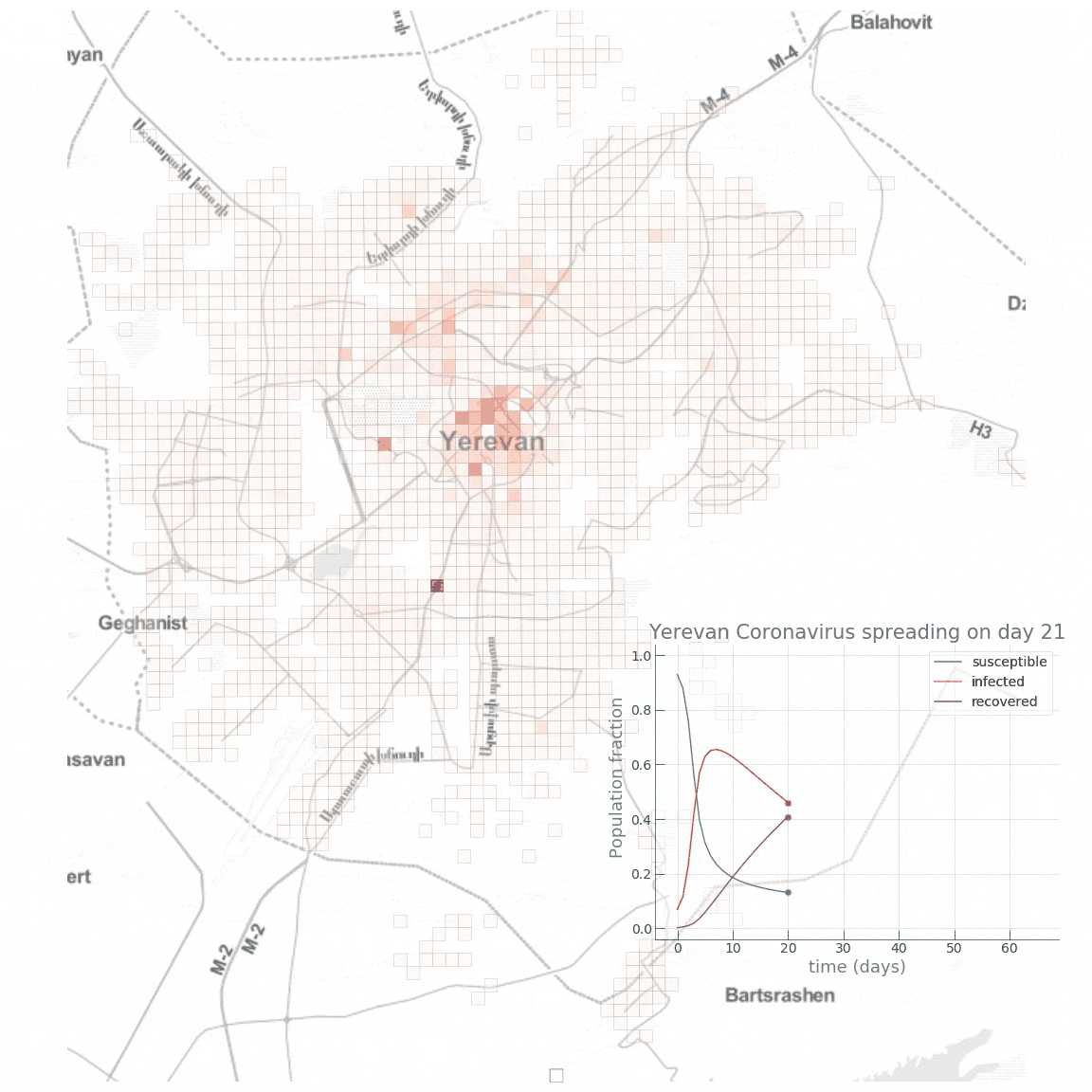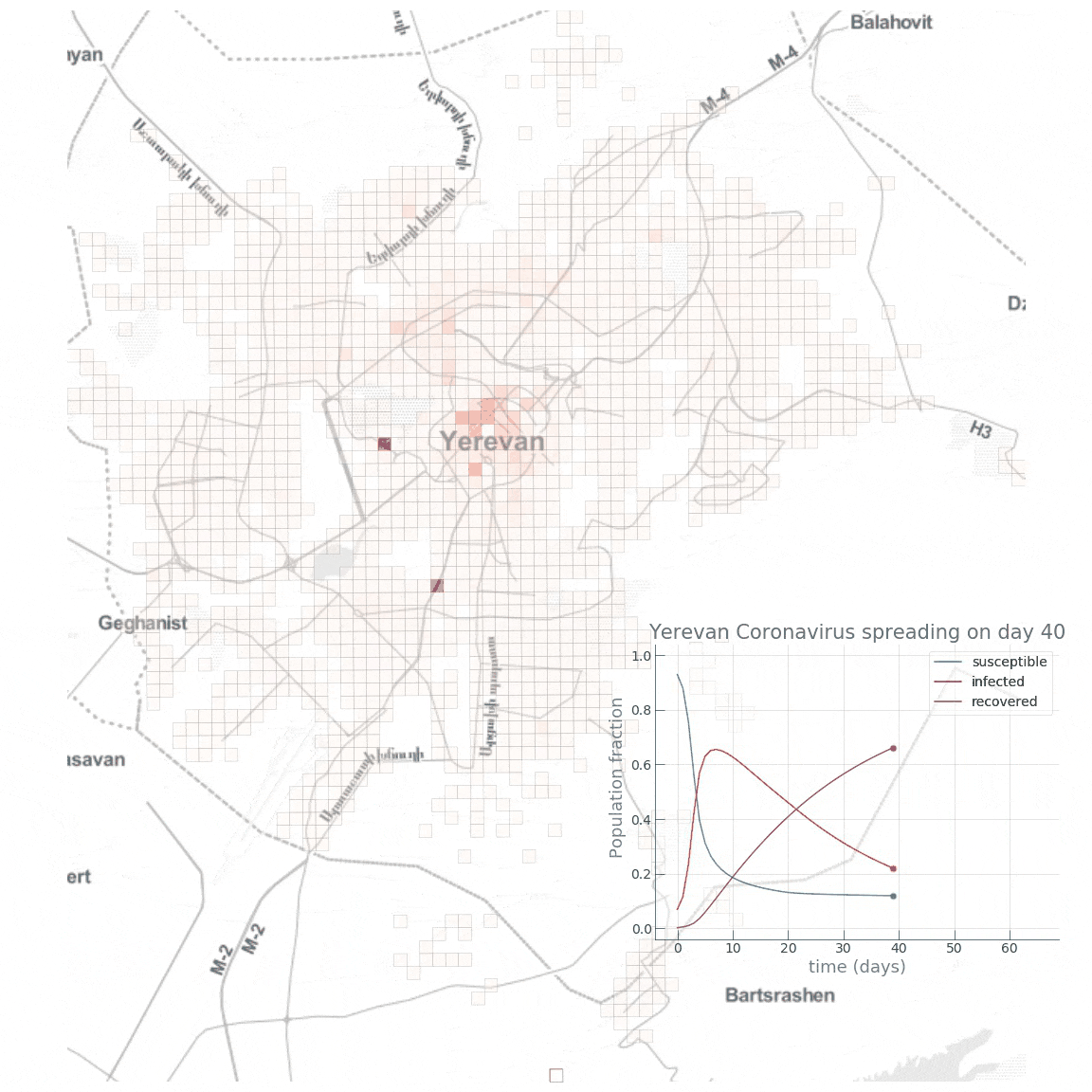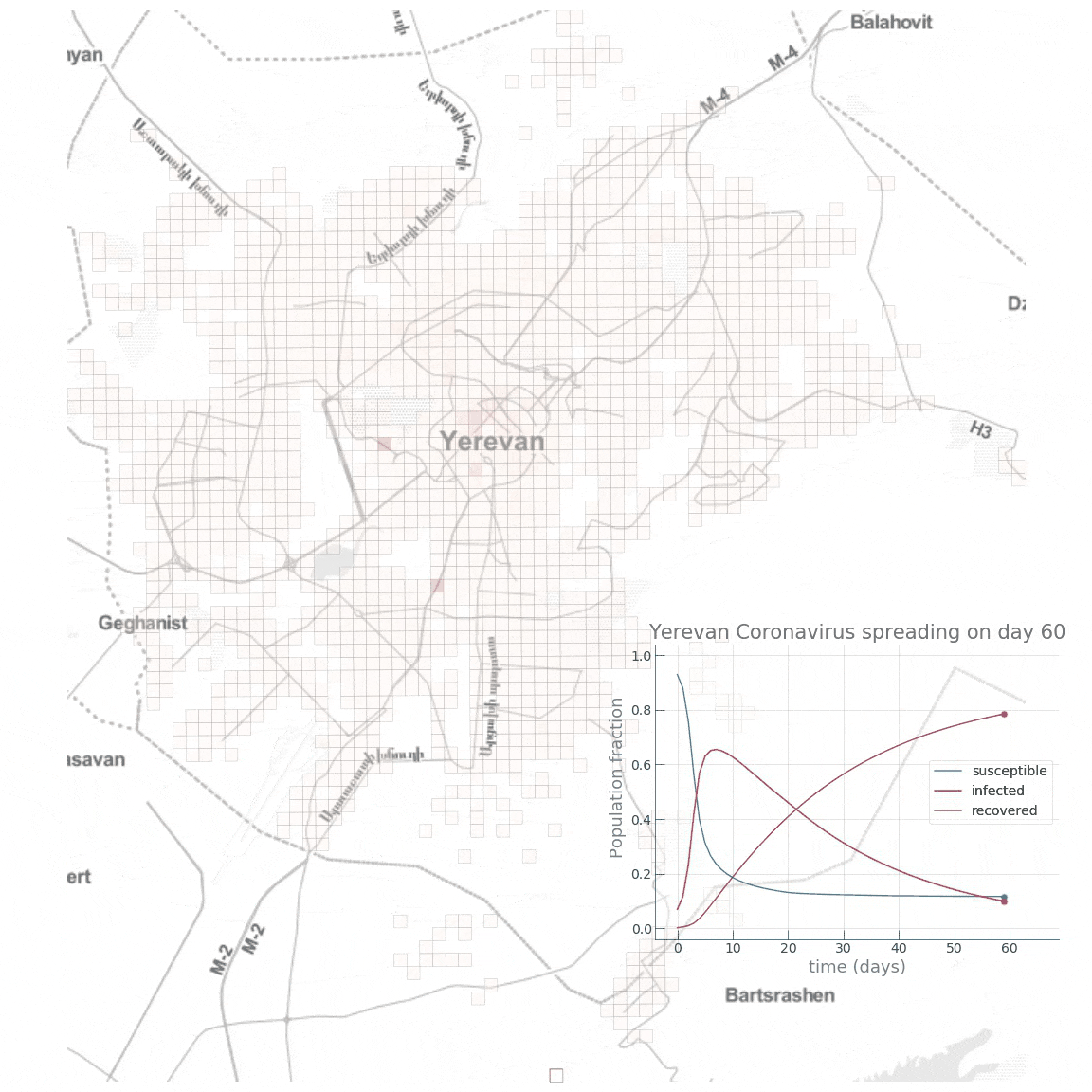
voir : The hidden patterns in complex global disease dynamics Les modèles distribués Les modèles agrégés tels que SEIR reposent sur des hypothèses très simplifiées dont les résultats, les prévisions locales, régionales et mondiales deviennent rapidement imprécises. Même en injectant des données plusieurs fois par jour, il est souvent difficile de déterminer à une ou deux semaines près quand surviendra le pic épidémique et dans quelle région du pays. Il faut alors réduire l'extension géographique du modèle et se limiter à un pays, avec des mesures de confinement et de quarantaine. Pour remédier à ces lacunes, les algorithmes sont régulièrement améliorés à mesure que l'on connaît mieux le virus et ses modes de transmission comme expliqué ci-dessus. C'est pour éviter cette simplification et des résultats approximatifs qu'on utilise également la deuxième catégorie, les modèles distribués. Ils ne se basent pas sur des modèles de groupes mais sur des données individuelles et des comportements sociaux, des variables environnementales et sociales qui sont déterminantes dans l'émergence et la propagation de la maladie. Ils s'appliquent principalement à toutes les maladies dites vectorielles, transmises par des vecteurs comme les moustiques ou d'autres animaux. L'avantage des modèles distribués est d'offrir des résultats très concrets permettant de guider les campagnes de désinfection jusqu'à l'échelle d'un quartier voire d'une rue comme c'est le cas dans les pays tropicaux (cf. les épidémies de dengue et autre chikungunya en Inde et en Thaïlande). Calibration et dépistage Même face à un virus inconnu comme le Covid-19, ces deux types de modèles fonctionnent assez bien car toutes les épidémies obéissent aux "lois de la nature" comme l'évolution, l'écologie, la biologie et la génétique. A partir des données qui donnent des courbes d'incidence des nouveaux cas quotidiennement et le suivi des contacts, on obtient l'intervalle sériel, c'est-à-dire le temps entre l'apparition des symptômes chez une personne et leur occurrence chez les autres personnes qu'elle a infectées. Cela permet également aux épidémiologistes de rechercher les foyers d'infections. Ensuite, il faut calibrer le modèle sur base des données statistiques et des connaissances sur le virus ou des virus du même groupe comme le SARS. Au début de l'épidémie et faute d'un grand nombre de données, les modèles se basent plutôt sur un comportement aléatoire ou stochastique. Mais au bout de quelques semaines, la loi des grands nombres s'applique : le taux de contamination tend à s'harmoniser dans la population. Les chercheurs peuvent alors envisager des modèles déterministes qui permettent de prévoir le pic épidémique, les éventuels foyers locaux et d'adapter les stratégies de contrôle. C'est dans ce cadre qu'il est important d'avoir rapidement un grand nombre de données et donc que l'État décide de procéder à des dépistages massifs. Si les données sont insuffisantes, la modélisation sera imprécise, le moindre écart de quelques pourcents sur la population infectée donnant des résultats très divergents. Recul et fin de l'épidémie A partir du moment où le modèle épidémique fonctionne, on peut dire qu'il suffit d'attendre que le "Ro" tombe en-dessous de 1 pour conclure que l'épidémie recule. Ensuite, si l'épidémie continue à régresser et que tout se passe bien, le modèle épidémique montrera avant même qu'on s'en rendre compte que l'épidémie est terminée. En pratique, l'OMS considère qu'il ne doit plus y avoir de cas de contamination durant deux fois la période d'incubation du virus soit 28 jours pour le Covid-19. Mais nous verrons quand nous ferons le bilan de la crise sanitaire de Covid-19, qu'en pratique la situation risque de ne pas être ausi simple et que le Covid-19 pourrait ne jamais disparaître, la Covid devenant endémique comme la grippe saisonnière. Ro et Re, les taux de reproduction de base et effectif Le concept de "taux de reproduction" fut imaginé à la fin du XIXe siècle par les démographes qui l'appelaient le "taux net de reproduction". Il désignait alors le taux d'accroissement ou de déclin d'une population. Cette notion fut ensuite introduite en médecine par le médecin britannique Sir Ronald Ross, spécialiste du paludisme, qui démontra en 1911 que la progression de la maladie peut être freinée efficacement dès que la population de moustiques descend sous un seuil critique. Ross fut l'un des premiers épidémiologistes à proposer de suivre l'évolution de la propagation d'une maladie au moyen d'un modèle mathématique. Le concept de Ro fut inventé en 1952 par le médecin britannique George MacDonald, également spécialiste du paludisme, pour décrire la transmission de cette maladie. Plus tard, en 1975, l'Allemand Klaus Dietz et l'Américain Herbert W. Hethcote élargirent la notion de Ro aux maladies contagieuses et contribuèrent à populariser son usage comme "métrique" pour une meilleure compréhension du déclenchement et de la propagation des épidémies. Pour évaluer le taux de contagiosité d'une maladie infectieuse, les scientifiques utilisent deux valeurs : Ro et Re. - Le Ro, prononcé "R zéro" ou "R au", est un terme mathématique qui indique la contagiosité d'une maladie infectieuse. Également appelé le taux de reproduction de base, Ro indique le nombre moyen de personnes qui contracteront une maladie contagieuse d'une personne contaminée par cette maladie. Il s'applique spécifiquement à une population de personnes qui était auparavant saine et qui n'a pas été vaccinée ou n'est pas immunisée, ce qu'on appelle les personnes susceptibles. En théorie, le Ro s'utilise uniquement au tout début d'une épidémie. Ensuite on utilise le Re. - Le Re (ou Rt) est le taux de reproduction effectif. Il désigne le nombre de nouveaux cas qu'une seule personne contaminée va engendrer en moyenne à un instant donné dans une population mixte composée à la fois de personnes susceptibles (pouvant être contaminées) et de personnes immunisées. Le Re est utilisé à mesure que l'épidémie progresse. Il évolue en fonction des mesures de contrôle (confinement, distanciation physique, mesures d'hygiène, etc). Le Re est constamment recalculé afin d'estimer la dynamique de l'épidémie et projeter son évolution. Souvent, par abus de langage les scientifiques utilisent le Ro à la place du Re, même dans des articles académiques. Quand les journalistes consultent ensuite ces articles, pour éviter les erreurs et mauvaises interprétations, ils recopient les textes et graphiques et évoquent donc également le Ro à la place du Re; quand ils évoquent un "Ro en hausse", il faut comprendre qu'il s'agit du Re. Même confusion sur les plateaux TV où à des fins de vulgarisation et rendre les choses plus faciles à comprendre, les scientifiques invités utilisent uniquement le Ro, et tant pis pour l'exactitude scientifique. Que signifie concrètement le Ro ou le Re ? Prenons un exemple. Si une maladie a un Ro = 5, une personne contaminée peut la transmettre en moyenne à 5 autres personnes ou contacts. Cette réplication se poursuivra si personne n'a été vacciné contre la maladie ou n'est pas immunisé. En général, suite à la vaccination, Ro ~ 0.5 comme dans le cas de la grippe saisonnière. Sans vaccination et en fonction de la transmissibilité du variant, ce taux peut facilement être multiplié par 10. Voici le Ro de quelques maladies :
Pour le Covid-19, au début de la pandémie, à l'époque où elle était hors contrôle, l'OMS déclara que Ro = 2.2. En février 2020, plusieurs études donnaient également un Ro variant entre 2.2 et 2.7 (cf. J.Rocklöv et al., 2020; Z.Lin et al., 2020; X.Zhang et al., 2020). En réalité, le modèle SIR appliqué rétrospectivement aux données de nombreux pays indique qu'il était deux fois plus élevé avec un Ro = 4.5 (cf. G.G. Katul et al., 2020). Une autre étude indique qu'au début de l'épidémie, à Wuhan, lorque le temps de doublement (voir plus bas) variait entre 2.2 et 3.3 jours, Ro = 5.7 (cf. R.Ke et al., 2020). Durant l'été 2021, le variant Delta augmenta le Ro entre 6 et 8. Bien que plus contagieux, fin 2021 le variant Omicron présenta un Ro entre 3 et 5. En revanche, le risque de recontamination était 5.4 fois plus élevé qu'avec le variant Delta (cf. ICL, 2021). Un Ro > 5 est le signe d'une maladie très infectieuse, similaire à celui de la rubéole ou de la polio. Des simulations réalisées durant les deuxième et quatrième vagues épidémiques montraient que Re pouvait dépasser 10, raison pour laquelle les gouvernement ont renforcé les mesures de protection sanitaire et accéléré les campagnes de vaccination. Pendant les confinements, dans certains pays d'Europe, on était parvenu à baisser Re < 0.6. En Belgique par exemple, en mai 2020 Re = 0.53, un record. En France, selon les données du système Si-DP, le 21 novembre 2020 Re = 0.56 avec un minimum record de Re = 0.35 le 26 novembre 2020 en Corse. Comment calcule-t-on le Ro d'un virus (ou d'une maladie) ? Le Ro dépend principalement de trois facteurs : la durée de la contagiosité après la contamination, la probabilité de contamination après un contact entre une personne contaminée et une personne susceptible et la fréquence des contacts humains. Plusieurs facteurs sont donc pris en compte :
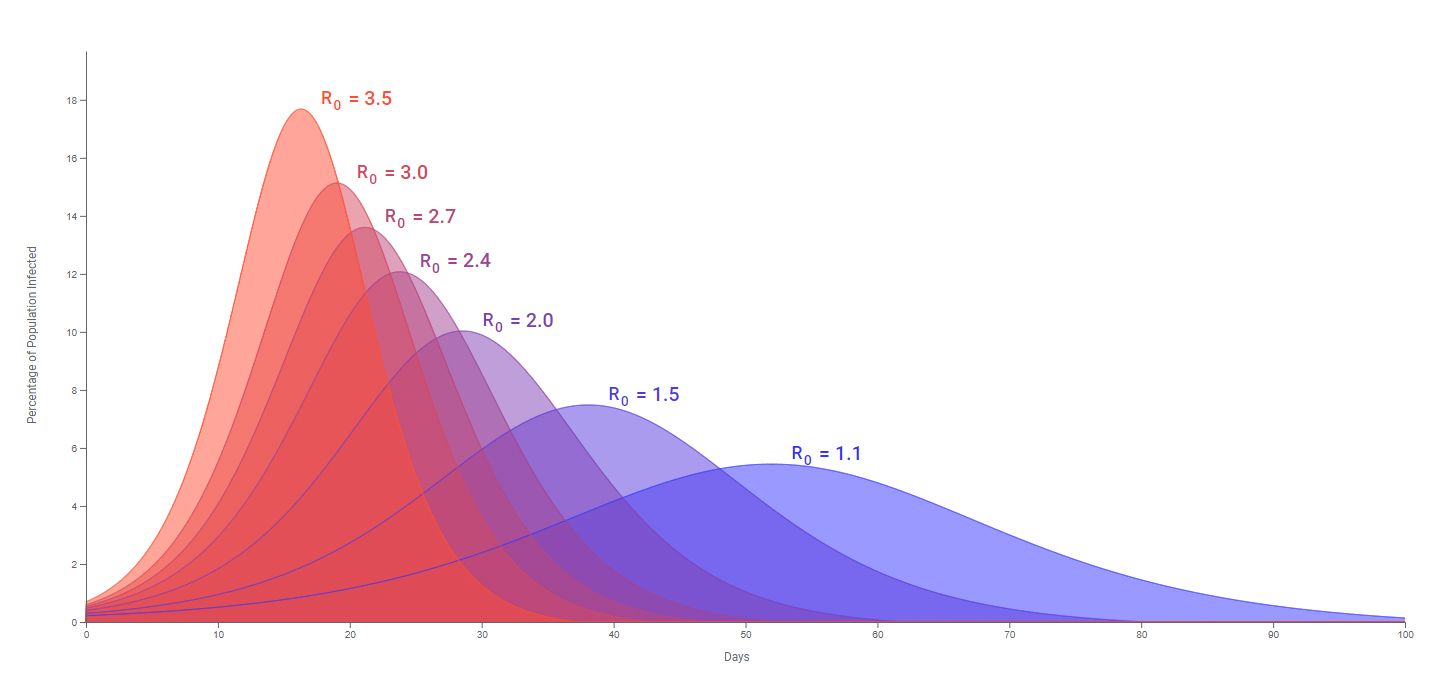
- La période de contamination. Certaines maladies sont contagieuses plus longtemps que d'autres. Pour certains virus comme celui de la grippe, les enfants peuvent également être contagieux plus longtemps. Plus la période de contamination est longue, plus il est probable qu'une personne atteinte transmette le virus à d'autres personnes ou contacts. Une longue période de contamination contribuera à une valeur Ro plus élevée. Autrement dit, le virus sera plus contagieux. - Le taux de contact. Si une personne contaminée par un virus contagieux entre en contact avec de nombreuses personnes saines et non vaccinées, le virus (mais pas nécessairement la maladie qui exige une infection) sera transmis plus rapidement. Si cette personne reste en isolement ou est mise en quarantaine durant toute la période où elle est est contagieuse, le virus ne se transmettra pas et sa propagation sera localement endiguée. Un taux de contact élevé contribuera à une valeur Ro plus élevée. - Le mode de transmission. Les maladies qui se transmettent le plus rapidement et le plus facilement sont celles dont les virus se propagent par l'air, comme la grippe ou la rougeole. Un contact physique avec une personne contaminée par un tel virus n'est pas nécessaire pour le transmettre (cf. les voies de transmission). En revanche, les maladies transmises par contact direct avec les fluides corporels (sang, salive, urine, sperme, etc), comme Ebola ou le VIH, ne sont pas aussi faciles à contracter ou à transmettre. Par conséquent leur Ro est peu élevé. Selon la valeur de Ro, on peut déterminer la progression de l'épidémie : Ro < 1 : chaque contaminé provoque moins d'une nouvelle contamination. Dans ce cas, le nombre de cas diminuera et le virus disparaîtra faute d'hôtes à contaminer. Ro = 1 : chaque contaminé provoque une nouvelle contamination. La propagation du virus reste stable mais il n'y a ni épidémie ni pandémie. Ro > 1 : chaque contaminé provoque plus d'une nouvelle contamination. Le virus se transmet à plusieurs personnes. On peut atteindre le stade d'épidémie ou de pandémie. Soulignons que la valeur Ro d'un virus ne s'applique que lorsque toute la population est vulnérable. Cela signifie que personne n'a été vacciné, personne n'a encore eu la maladie et il n'y a aucun moyen de contrôler la propagation du virus. Cette combinaison de conditions est rare de nos jours grâce aux progrès de la médecine. On peut aussi calculer combien de personnes devraient être vaccinées ou auto-immunisées pour stopper une épidémie. Pour le savoir, il suffit de connaître le Ro du virus. Ce pourcentage se calcule à partir de la relation suivante : Pourcentage de la population à vacciner (ou auto-immunisée) = (1- (1/Ro)) x100
Effet du Ro sur la courbe épidémique. Document TIBCO. Par exemple, pour un Ro = 3, cela représente 66% de la population. Pour un Ro = 5.7, cela représente 82% de la population (cf. P. Fine et al., 2011). Pour rappel, dans le cas du Covid-19, en raison du confinement et des gestes barrières appliquée en Europe, en moyenne entre 5 et 15% de la population était auto-immunisée en novembre 2020 soit après ~9 mois au contact du virus. La proportion la plus élevée s'observait chez le personnel de la santé avec 17% de personnes auto-immunisées ainsi que dans les grandes villes avec 26% d'auto-immunisés à Bruxelles (cf. Sciensano) et 30% à Stokholm (cf. NPR). Le taux de létalité Le taux de létalité est la proportion de décès chez les patients atteints d'une affection donnée, par exemple par la Covid-19. Cependant, beaucoup de rédacteurs le confondent avec le taux de mortalité bien connu qui représente le nombre annuel de décès dûs à une cause rapporté au nombre d'habitants de la zone considérée.
La plupart des chercheurs et journalistes professionnels anglo-saxons (cf. The Lancet, The New York Times) utilisent le taux de létalité des cas confirmés (CFR ou Case Fatality Rate) qu'ils différencient du taux de létalité des cas de contamination (IFR ou Infection Fatality Rate). Le CFR correspond au taux de létalité utilisé en francophonie. L'IFR tient compte de la possibilité de ne pas avoir détecté tous les cas de contamination (toutes les personnes positives mais non testées). Si deux fois plus de personnes sont contaminées mais non détectées, on peut obtenir un IFR trois fois inférieur au CFR comme on le voit à gauche. Dans le cas de la Covid-19, il faudrait que tout le monde utilise le taux de létalité en tenant compte des cas de contamination non détectés, c'est-à-dire l'IFR. Mais on peut difficilement l'utiliser car le nombre total de cas de contamination est inconnu puisque toute la population n'a pas été testée. Certains chercheurs ont essayé d'estimer le nombre total de cas pour calculer l'IFR. La proportion d'auto-immunisation ajoutée aux malades non détectés varie entre 1 et ~30% de la population. Cette incertitude est trop grande pour calculer l'IFR avec précision. Les modèles souffrent donc d'une imprécision sensible qui ne sera levée qu'une fois le dépistage massif terminé. Une mauvaise utilisation des termes et donc des formules peut semer la confusion dans l'esprit du public et donner des chiffres très différents comme l'ont rappelé les membres de l'ONG Global Change Data Lab qui gère en collaboration avec des chercheurs de l'Université d'Oxford le site "Our World Data" qui publie des statistiques sur la pandémie de Covid-19. Ceci dit, à partir du Ro, du taux de létalité des cas de contamination (IFR) et du taux de transmissibilité (ou de contagiosité), on peut déterminer le nombre théorique de décès provoqué par le virus. Pour un Ro=2, un IFR = 0.6%, un temps de génération de 6 jours et 1000 personnes contaminées, on aboutirait à 1000 x 25 x 0.6% soit 192 morts au bout d'un mois. Si l'IFR augmente de 50% (IFR=0.9%), cela donnerait 288 morts. Mais si le taux de transmissibilité augmentait de 50%, le calcul devient 1000 x (2 x 1.5)5 x 0.6% soit 1458 décès. Autrement dit, à paramètres constants, une mutation virale plus transmissible (plus contagieuse) est plus redoutable qu'une mutation plus mortelle. La précision des prévisions Nous avons expliqué précédemment que la plupart des pays furent incapables de prévoir l'évolution de l'épidémie avec une précision inférieure à environ deux semaines. La deuxième vague épidémique apparue entre mars et avril 2020 en Asie n'a pas été prévue non plus, juste anticipée en voyant le nombre de cas réaugmenter suite aux contaminations importées. Plusieurs facteurs peuvent expliquer cette imprécision parmi lesquels la sous-estimation du nombre de cas de contaminations. En effet, face à l'épidémie on doit reconnaître que la Belgique a opté pour une méthode de calcul et de comptabilisation des cas les plus larges possibles qui a donné d'excellents résultats. Selon le virologue Emmanuel André, porte-parole du centre de crise durant la première vague épidémique, cette méthode que beaucoup de pays n'ont pas appliquée au départ en pensant bien faire est utilisée "par de plus en plus de pays qui commencent à copier le modèle belge". A tester : COVID-19 Event Risk Assessment Planning Tool SimPandemic, Science Buddies
En Belgique, les experts ont choisi de tenir également compte des personnes qui sont décédées dans des hôpitaux des suites du Covid-19 et pour lesquelles des tests ont pu être réalisés ainsi que des cas suspects de Covid-19. Ces cas concernent des personnes décédées qui n'ont pas pu être testées mais qui présentent une forte suspicion d'avoir succombé au Covid-19. C'est la raison pour laquelle le centre de crise a également comptabilisé les décès suspects dans les maisons de repos, des données que d'autres pays n'ont pas pris en compte comme l'Espagne, l'Angleterre, le Pays de Galles, la Lombardie et la France jusqu'au 2 avril. Ces données complémentaires n'étant pas ajoutées aux critères de base, les chiffres officiels de létalité ont vraisemblablement été fortement sous-évalués. Par conséquent, les prévisions calculées par leurs modèles sont également moins précises et ne colleront jamais tout à fait à la réalité tant qu'ils ne seront pas ajustés. L'intérêt d'analyser les flux numériques Au cours de la dernière décennie, des méthodologies innovantes ont vu le jour pour suivre la propagation des épidémies au niveau de la population à l'aide de sources de données non conçues à cet effet. Ces approches ont exploité des informations numériques provenant d'Internet et des moteurs de recherche des cliniciens, des reportages, des systèmes participatifs de surveillance des maladies, des microblogs Twitter, des dossiers de santé électroniques, du trafic sur Wikipédia, des appareils portables, des thermomètres connectés à un smartphone et des sites Internet des agences de voyage pour estimer la prévalence de la maladie en temps quasi réel. Plusieurs de ces outils ont déjà été utilisés pour suivre l'évolution de la pandémie de Covid-19.
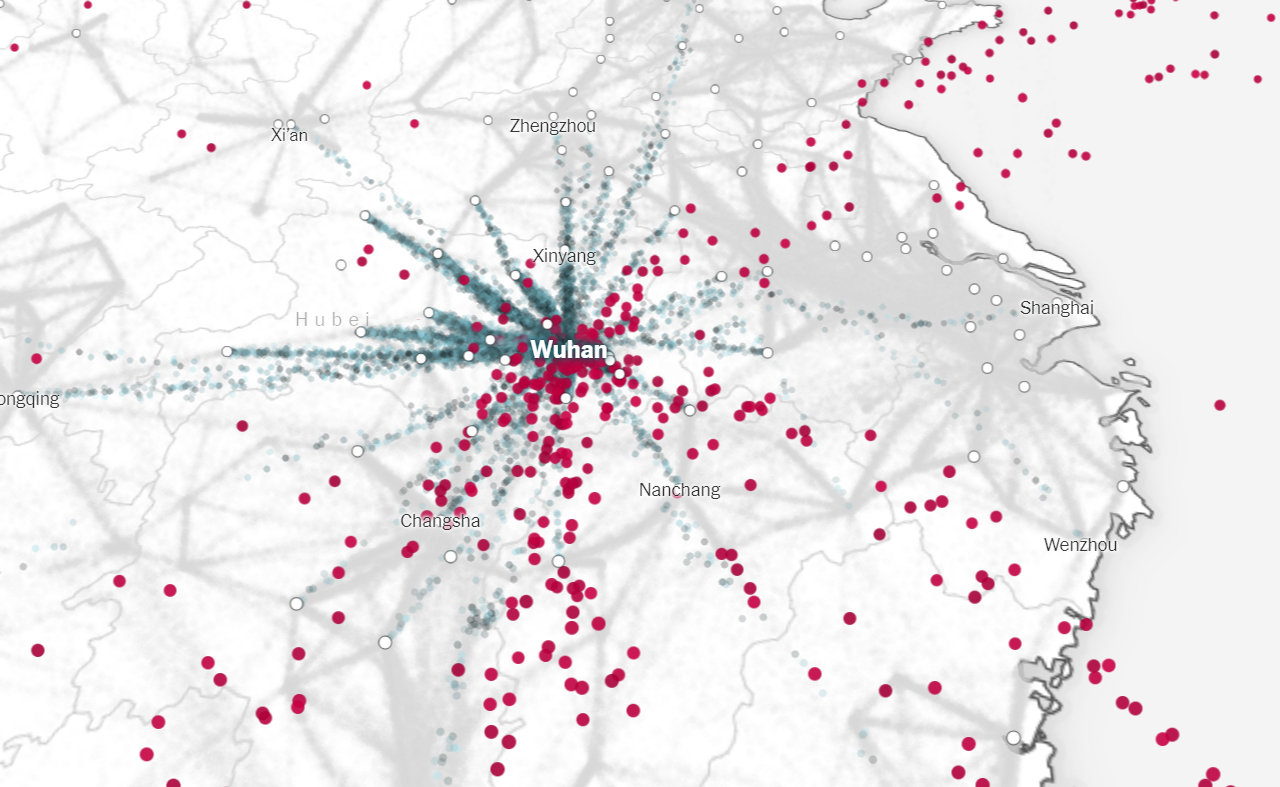
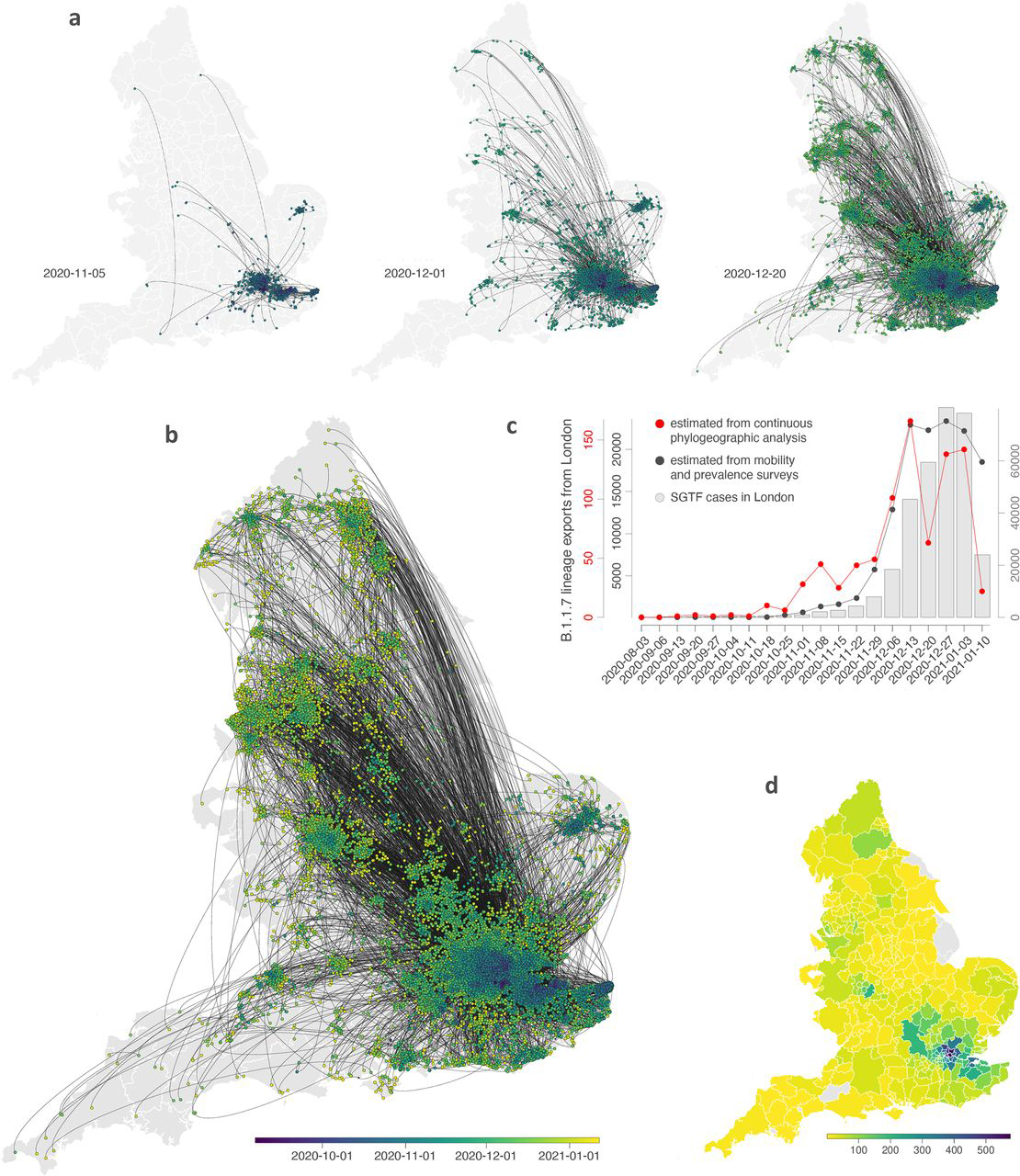
Ces sources de données peuvent toutefois présenter des biais. L'activité de recherche sur Google par exemple est sensible à l'intensité de la couverture des actualités. Les méthodologies pour atténuer les biais dans les sources de données numériques impliquent généralement de combiner l'histoire de la maladie, les modèles mécanistes et les enquêtes pour produire des estimations de tendances non biaisées de l'activité de l'épidémie. Cette méthode fut notamment appliquée pour étudier la propagation de l'épidémie au Covid-19 en Chine en janvier 2020 et la propagation du variant Alpha (B.1.1.7) au Royaume-Uni (qui durant la pandémie fut 2 mois en avance sur l'état sanitaire en Europe continentale). Pour la Chine, nous avons expliqué que les chercheurs ont analysé les données anonymisées des téléphones portables et constaté qu'environ 7 millions de personnes avaient quitté Wuhan avant que la ville ne soit confinée. Parmi elles, il y avait 85% de contaminés. Si à l'époque les autorités avaient pu prévoir et endiguer ce pénomène à la source, on aurait peut-être éviter la pandémie. Il faut donc en tirer les leçons. En attendant que toute la population soit vaccinée ou auto-immunisée, dans une étude publiée dans la revue "Science Advances" le 5 mars 2021, l'équipe de l'informaticien Mauricio Santillana, directeur du Machine Intelligence Research Lab à l'Hôpital pour enfants de Boston, analysa l'activité des flux de données numériques extraits des GSM durant la pandémie. Leur idée était de trouver une méthode pour "anticiper l'augmentation des cas confirmés et des décès de 2 à 3 semaines". Cela laisse ainsi quelques semaines aux autorités d'organiser une contre-mesure non pharmaceutique ciblée (par exemple une réduction de la taille de la bulle sociale, un reconfinement temporaire partiel, une réorganisation des centres de santé, etc). Les chercheurs proposent "un moyen d'harmoniser ces flux de données pour identifier les futures épidémies de Covid-19". En effet, selon les chercheurs, "la combinaison des données disparates sur la santé et le comportement peut aider à identifier les changements d'activité de la maladie des semaines avant l'observation en utilisant la surveillance épidémiologique traditionnelle". Cette technique faisant appel à l'IA combinée à l'analyse contextuelle et aux "Big Data" peut s'avérer très fiable et a déjà prouvé son efficacité pour détecter des évènements avant même que les autorités en soient conscientes (cf. BlueDot).
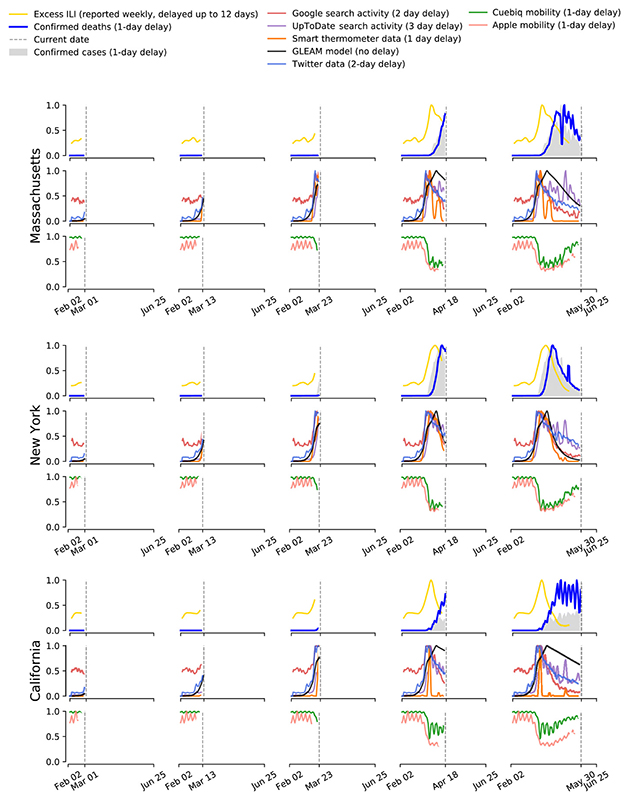
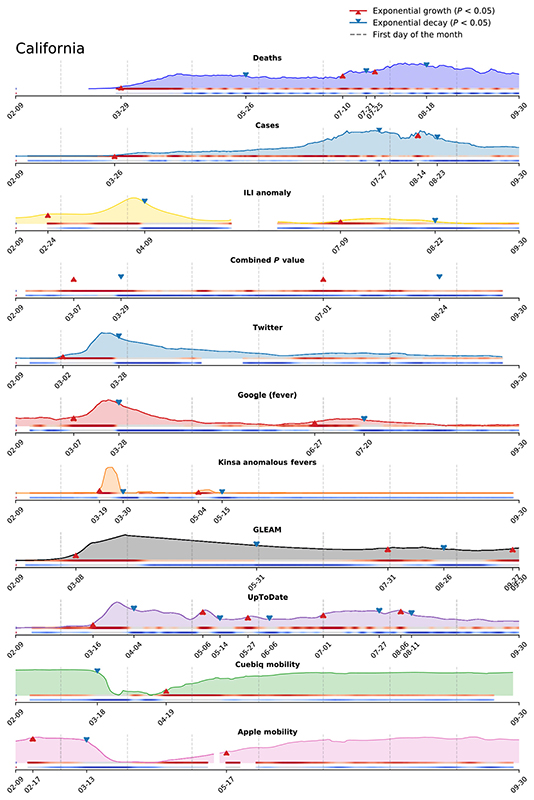
Les auteurs proposent d'utiliser plusieurs sources de données numériques afin d'obtenir une indication plus précoce de la propagation de l'épidémie que les mesures traditionnelles telles que les cas confirmés ou les décès. Ils ont tenu compte de six sources de données : - Les modèles Google Trends pour une suite de termes liés au Covid-19 - Les activités sur Twitter liées au Covid-19 - Les recherches de cliniciens liées au Covid-19 à partir d'UpToDate - Les prévisions du modèle global d'épidémie et de mobilité (GLEAM) - Des données de mobilité humaine anonymisées et agrégées à partir des smartphones - Les mesures du thermomètre intelligent Kinsa (connecté par Bluetooth). Chacun de ces "proxies" de l'activité du Covid-19 est analysé pour déterminer son avance ou son retard par rapport aux mesures traditionnelles de l'activité épidémique des cas confirmés, des décès attribués et des données d'ILINet (le réseau américain ambulatoire de surveillance des maladies pseudo-grippales). Ensuite, ces données sont combinées dans une estimation multiproxy pour calculer la probabilité d'une épidémie imminente de Covid-19 et le moment auquel surviendra une telle épidémie sur la base de la variabilité multiproxy. Comme on le voit dans les graphiques présentés ci-dessus, les chercheurs ont ainsi pu établir deux prévisions. La première pour une période de "formation" de l'épidémie allant du 1er mars au 31 mai 2020, la seconde pour une période de "validation" allant du 1er juin au 30 septembre 2020. Selon les chercheurs, "Si les résultats sont cohérents avec la réalité, ils augmenteraient la confiance dans le fait qu'ils peuvent capturer les changements futurs dans la trajectoire de l'activité du Covid-19". Comment interpréter les courbes ? En cas d'épidémie infectieuse, il est important non seulement d'étudier le nombre de contaminés et de décès, mais également le taux de létalité car un taux de croissance rapide peut conduire en quelques semaines à un grand nombre de morts. Pour évaluer la situation, les experts calculent combien de temps il faut pour que le nombre de décès confirmés double, c'est le temps de doublement. Prenons un exemple. S'il y a trois jours il y avait 500 décès confirmés au total et aujourd'hui il y en eu 1000, alors le temps de doublement est de trois jours. Dans le cas d'une croissance exponentielle, 500 décès au départ signifie qu'on atteindra plus d'un million de décès après 11 doublements et 1 milliard de décès après 10 doublements supplementaires ! Plus le temps est court, plus la maladie se propage rapidement. Au début de la propagation du Covid-19, les chercheurs estimaient le temps de doublement entre 2 et 3 jours selon les pays et les populations, ce qui est très rapide. Le temps de doublement des décès évolue dans le temps mais on ne peut pas simplement extrapoler la valeur actuelle pour calculer combien de personnes vont mourir dans une semaine ou dans un mois. En effet, le nombre de décès peut être faible ou constant pendant quelques jours puis soudainement il peut doubler pendant une courte période, suivant une croissance exponentielle. Si pendant une épidémie, le temps nécessaire pour que les décès doublent reste constant, on en déduit que la maladie se propage toujours de façon exponentielle et que le pic épidémique n'est pas encore atteint. Télécharger les données sur l'épidémie au Covid-19 : ECDC - Worldometer
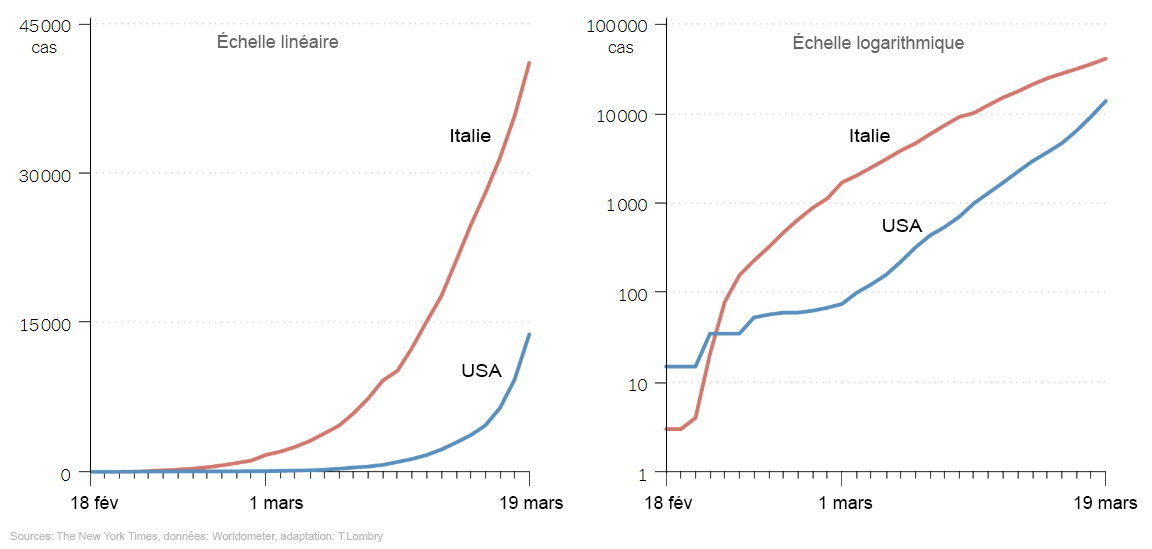
Ainsi comme l'indique en temps réel le site Our World Data, le 2 avril 2020 (pour ne pas croire que c'est le poisson d'avril), le temps de doublement des décès était respectivement de : - 2 jours au Cameroun, Russie, Chili, ... - 3 jours au Royaume-Uni, Etats-Unis, Afrique du Sud, ... - 4 jours en Belgique, Serbie, Taiwan, ... - 5 jours en France, Pays-Bas, Canada, ... - 6 jours au Luxembourg, Suisse, Espagne, ... Il était retombé à 16 jours en Corée du Sud et à 46 jours en Chine, portant la moyenne mondiale à 7 jours. Cela ne signifie pas que localement, au coeur même d'un pays, on n'observe pas des différences. En fonction du respect ou non des mesures de confinement et des gestes barrières par exemple et donc de la propagation de la vague épidémique, une province ou même une ville peut être en avance ou en retard sur une autre partie du pays comme on l'observa en France ou la région Est fut touchée avant la Bretagne. Les psychologues nous disent que les humains visualisent et interprètent plus facilement des processus à croissance linéaire et les petits nombres (1, 2, 3,...) que des progressions exponentielles qui conduisent rapidement à des grands nombres (10, 100, 1000, ...). Par facilité, nous avons tendance à tout décrire par des processus linéaires, même si nous savons que cela ne représente pas correctement la réalité. C'est ce qu'on appelle le biais de croissance exponentiel. Sachant cela, pour mieux visualiser l'évolution d'une épidémie, il suffit de projeter les données sur un axe X du temps ou sur un axe Y du nombre de contaminés ou de décès en échelle logarithmique comme on le voit ci-dessus. Ainsi, là où une échelle linéaire affichera une courbe exponentielle, l'échelle logarithmique affichera une courbe plus ou moins droite. De cette façon, lorsque le nombre de cas (contaminés ou décès) diminuera, on constatera un fléchissement progressif de la courbe vers les plus petites valeurs, indiquant un ralentissement du nombre de cas. On pourra donc espérer voir la fin de l'épidémie.
Mais ici également il faut pouvoir interpréter correctement les courbes. Ainsi, si pour un pays déterminé le temps de doublement du nombre décès reste élevé (admettons 5 jours), cela n'implique pas nécessairement que l'épidémie n'est pas maîtrisée. En effet, si en même temps on observe une courbe de contamination logarithmique qui se courbe lentement vers le bas (comme celle de l'Italie ci-dessus à droite), on peut affirmer que l'épidémie est sous contrôle. C'était par exemple le cas en Italie à partir de la mi-février 2020 et en Belgique à partir de début avril 2020. Mais contrôler l'épidémie ne veut pas dire qu'il y aura peu de décès ou pas de nouvelles vagues. On reviendra sur l'effet des variants sur l'immunité collective et sur l'élimination des bactéries et virus. Ceci dit, malgré cette analyse toute mathématique, il reste que la réalité est faite d'impondérables, d'inconnues et que le monde est fait de personnes et notamment de politiciens qui peuvent se tromper (qui peuvent aussi changer d'avis) et d'un certain nombre de citoyens qui s'opposent aux mesures sanitaires, deux facteurs qui peuvent sérieusement empêcher d'atteindre les résultats des prédictions informatiques. Pour plus d'informations Sur ce site Les voies de transmission du Covid-19 Propagation de la pandémie de Covid-19 La gestion de la crise sanitaire de Covid-19 Modèles et simulateurs Covid-19 Stability Calculator, DHS.gov Covid Surface Decay Calculator, DHS.gov COVID-19 Event Risk Assessment Planning Tool Modélisation COVID-19, dont Omicron, Institut Pasteur SimPandemic, Science Buddies Biorender (logiciel de DAO) Calculer votre probabilité de survie si vous êtes contaminé par le Covid-19, Avi Schiffmann Coronavirus : l’équation de l’épidémie, Pour la Science, 2020 Comment fonctionnent les modèles qui prédisent l’évolution de la pandémie ?, Pour la Science, 2020 Covid-19 : comment sont conçus les modèles des épidémies ?, CNRS, 2020 Simulateur de l'épidémie au Covid-19 How epidemiological models of COVID-19 help us estimate the true number of infections, Our World in Data Physics in the Age of Contagion: The Bifurcation of COVID-19, Part2, Part 3, D.Nolte Second Version of a COVID-19 Simulator (MATLAB), Cleve Moler |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




{kind=link}